
{kind=link}
tg-me.com/levels_of_abstraction/27
Last Update:
почему ИИ-революция случилась именно сейчас?
уже несколько лет подряд ИИ делает то, что раньше считалось невозможным, компании инвестируют миллиарды в обучение все больших нейросетей, а люди вокруг повсеместно становятся “экспертами” (и я сам часть этой проблемы 🙃). но после того как мир увидел chatGPT, порой кажется, что сознательные роботы / сингулярность / AGI / восстание машин (нужное подчеркнуть) уже на пороге. а это действительно нечто совсем иное, чего в раньше не происходило никогда. и даже тест Тьюринга, концептуально разделяющий людей и роботов весь ХХ век, дал трещину — роботы все лучше притворяются людьми, а людям все сложнее доказать, что они не роботы, решая усложняющиеся капчи.
но что случилось такого, чего не происходило раньше? и действительно ли это технологическая "революция", которую энтузиасты сравнивают с изобретениям электричества, или обыкновенное линейное развитие прогресса, которое мы видели и раньше?
1️⃣ Данные. C момента изобретения письменности мы накопили очень много знаний о мире, а затем аккуратно и положили их все в интернет. Одна википедия — вершина человеческой техногенной цивилизации, обеспечившая доступом к информации каждого, у кого есть хотя бы старенький смартфон (дайте ей денег за это). И хотя мы сами временами используем это сокровище не самыми рациональным способом (слишком много мемов), обучение нейросетей упростилось радикально — бесплатные данные доступны в огромных количествах.
для масштаба: самая большая открытая языковая модель LLAMA-3 во время обучения видела ~75 терабайт текста, которые помимо википедии включают в себя весь открытый интернет, мировую литературу, реддит, твиттер, ArXiv c научными статьями, Github репозитории, и все это на 30 языках.
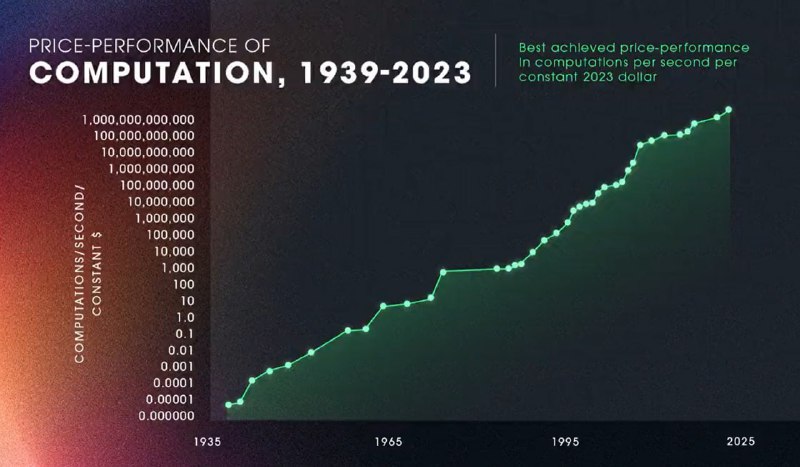
2️⃣ Вычислительные мощности. Их измеряют количеством вычислений в секунду и всю историю человечества эта скорость растет. закон Мура говорит о том, что количество транзисторов на процессоре увеличивается вдвое каждые ~два года, а Рэй Курцвейл заметил, что это справедливо не только для процессоров, но и для вычислительных мощностей всего человечества в целом, которые увеличиваются с экспоненциальной скоростью последние 100 лет, начиная с электромеханических арифмометров и заканчивая GPU гигантскими кластерами (картинка)
3️⃣ Вычислительные архитектуры (нейросети, глубокое обучение, трансформеры, RL). Соединение вычислительных мощностей с данными не создавало чуда, пока ученые не изобрели способ переноса знаний из текстов в код, подобный обучению детей. Для этого потребовалась очень длинная цепочка изобретений начиная от первых нейронных сетей еще в 1958 (без достаточно мощных компьютеров, они долго пролежали без дела), до обратного распространения ошибки (backpropagation), обучения с подкреплением (reinforcement learning) и появления архитектуры нейросетей "трансформер", которая стала стандартом для больших языковых моделей и до сих пор повсеместно используется в большинстве LLM, которые мы используем. и именно Трансформеры ответственны за T в аббревиатуре GPT (хотя ее изобретатели "просто" пытались улучшить google translate, но это отдельная история). а про обучение нейросетей у меня был отдельный пост.
4️⃣ Деньги. Все элементы выше какое-то время сосуществовали вместе, пока в ~2020 году небольшой, но амбициозный стартап openAI не вложил ~100 млн $ в рискованное мероприятие — обучение самой большой на тот момент языковой модели GPT-3 на 175 млрд параметров. гипотеза о связи размера сети и длительности обучения с конечной "интеллектуальностью" модели, еще не была подтверждена экспериментально, а поскольку проверка стоила колоссальных ресурсов, никто не спешил делать это первым.
рискованная ставка openAI выстрелила и надолго сделала их лидерами области. а подтверждение закона масштаба запустило гонку бюджетов. то что нам сейчас кажется примитивной технологией древних людей (помните GPT-3?), показало всему биг-теху, что сжигать деньги на GPU — самое благородное дело 2020-х, и конца тому не видно
🟦 Итого: ИИ революция = большие данные Х вычислительные мощности Х глубокое обучение X огромные деньги
#AI #history
BY уровни абстракции
Share with your friend now:
tg-me.com/levels_of_abstraction/27